
Tag

The development of open research data has generally been from the perspective of producers sharing data; we argue that it is vital to include the consumer perspective. In this blog post, we report insights gained from a workshop held in November 2024 exploring data reuse from different perspectives.
Kathleen Gregory, Femmy Admiraal, Pascal Flohr, Andrew S. Hoffman, Sarah Lippincott and Thed van Leeuwen •

This blog post presents preliminary findings from an exploratory study on independent researchers, using OpenAlex data to trace their research interests and career paths. We also discuss our experience working with open and federated data solutions during the study.
Camilla Lindelöw and Eline Vandewalle •


In 2022, we published a dataset of Scholars on Twitter. This blog post introduces an update to this dataset and discusses some of the challenges with our data providers: Twitter, Crossref, and OpenAlex. These challenges made the original dataset and process obsolete and this update necessary.
Philippe Mongeon, Timothy D. Bowman, Rodrigo Costas and Wenceslao Arroyo-Machado •

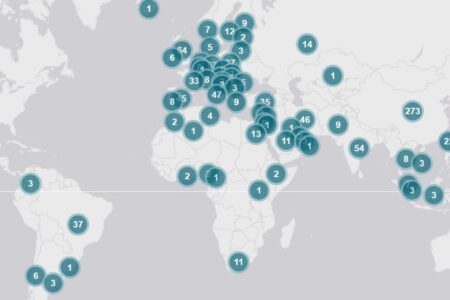
This post introduces the Open Edition of the CWTS Leiden Ranking, published today by CWTS in collaboration with the Curtin Open Knowledge Initiative, Sesame Open Science, and OurResearch. The Leiden Ranking Open Edition is the first fully transparent university ranking.
Ludo Waltman, Nees Jan van Eck, Martijn Visser, Mark Neijssel, Lucy Montgomery, Cameron Neylon, Bianca Kramer, Kyle Demes and Jason Priem •

Today, CWTS released the Open Edition of the Leiden Ranking. This blog post discusses the data curation approach taken in this fully transparent edition of the Leiden Ranking.
Nees Jan van Eck, Martijn Visser and Ludo Waltman •

